Cloud Services
Finding the perfect server size for your cloud deployment
Saturday, November 24, 2018

|
Bill Supernor |
Cloud server sizing can be a difficult thing to navigate, Bill Supernor gives his professional opinion to developers by going through the data.
Serving sizing in the cloud can be tricky. Unless you are about to do some massive high-performance computing project, super-sizing your cloud virtual machines/instances is probably not what you are thinking about when you log in to your favorite cloud service provider. But from looking at user data, it certainly does look like a lot of folks are walking up to their neighborhood cloud provider and saying exactly that: Super Size Me!
Like at a fast-food place, buying in the supersize means paying extra costs...and when you are looking for ways to save money on cloud costs, whether for production or non-production resources, the first place to look is at idle and underutilized resources.
Within the ParkMyCloud SaaS platform, we have collected bazillions (scientific term) of samples of performance data for tens of thousands of virtual machines, across hundreds of customers, and the average of all “Average CPU” readings is an amazing (even to us) 4.9%. When you consider that many users are already addressing underutilization by stopping or “parking” their instances when they are not being used, one can easily conclude that the server sizing is out of control and instances are tremendously overbuilt. As cool as “supersizing” sounds, the real solution is in rightsizing, and ensuring the instance size and type are better tailored to the actual.
Size, Damned Size, and Statistics
Before we start talking about what is involved in rightsizing, let’s look at a few more statistics, just because the numbers are pretty cool. Looking at utilization data from about 88.9 million instance-hours on AWS - that’s 10,148 years - we find the following:
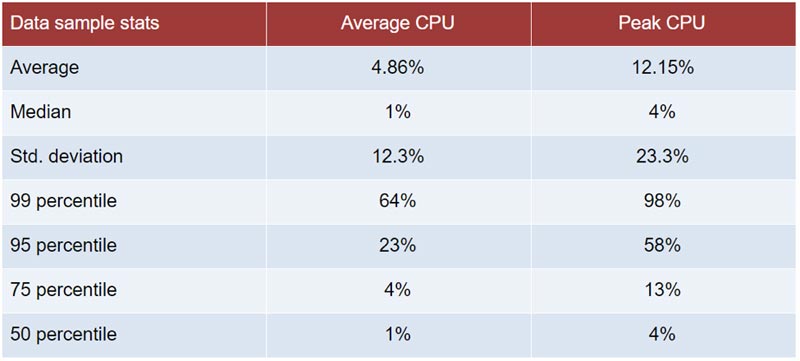
So, what is this telling us about server sizing? The percentiles alone tell us that more than 95% of our samples are operating at less than 50% Average CPU - which means if we cut the number of CPUs in half for most of our instances, we would probably still be able to carry our workload. The 95th percentile for Peak CPU is 68%, so if we cut all of those CPUs in half we would either have to be OK with a small degradation in performance, or maybe we select an instance to avoid exceeding 99% peak CPU (which happens around the 93rd percentile - still a pretty massive number).
Looking down at the 75th and 50th percentiles we see instances that could possibly benefit from multiple steps down! As shown in the next section, one step down can save you 50% of the cost for an instance. Two steps down can save you 75%!
Before making an actual server sizing change, this data would need to be further analyzed on an instance by instance basis - it may be that many of these instances have bursty behavior, where their CPUs are more highly utilized for short periods of time, and idle all the rest of the time. Such an instance would be better of being parked or stopped for most of the time and only started up when needed. Or...depending on the duration and magnitude of the burst might be better off moving to the AWS T instance family, which accumulates credits for bursts of CPU, and is less expensive than the M family, built for a more continuous performance duty cycle.
Hungry Size
On every cloud provider, there is a clear progression of server sizing and prices within any given instance family. The next size up from where you are is usually twice the CPUs and twice the memory, and as might be expected, twice the price.
Here is a small sample of AWS prices in us-east-1 (N. Virginia) to show you what I mean:
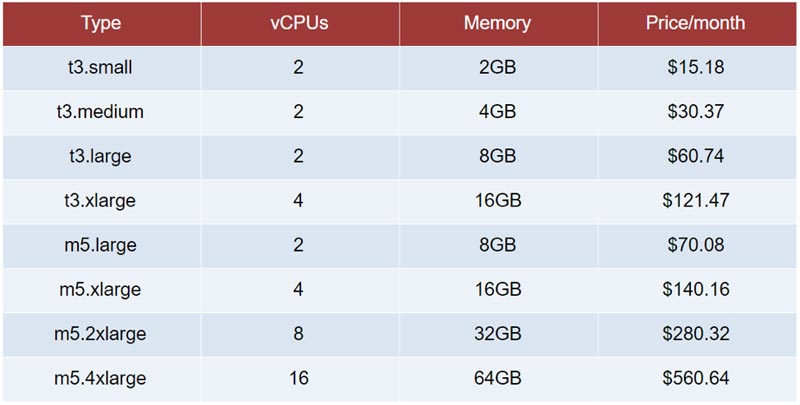
Double the memory and/or double the CPU...and double the price.
Pulling the Wool Over Your Size?
It is important to note that there is more to instance utilization than just the CPU stats. There are a number of applications with low-CPU but high network, memory, disk utilization, or database IOPs, and so a complete set of stats are needed before making a rightsizing decision.
This can be where rightsizing across instance families makes sense.
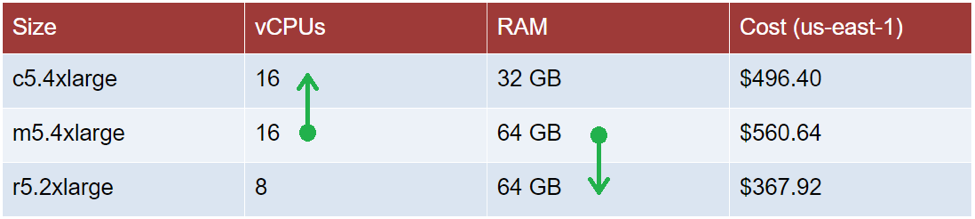
On AWS, some of the most commonly used instance types are the T and M general purpose families. Many production applications start out on the M family, as it has a good balance of CPU and memory. Let’s look at the m5.4xlarge as a specific example, shown in the middle row below.
If you find that such an instance was showing good utilization of its CPU, maybe with an Average CPU of 75% and Peak CPU of 95%, but the memory was extremely underutilized, maybe only consuming 20%, we may want to move to more of a compute-optimized instance family. From the table below, we can see we could move over to a c5.4xlarge, keeping the same number of CPUs, but cutting the RAM in half, saving about 11% of our costs.
On the other hand, if you find the CPU was significantly underutilized, for example showing an Average CPU of 30% and Peak of 45%, but memory was 85% utilized, we may be better off on a memory-optimized instance family. From the table below, we can move to an r5.2xlarge instance cutting the vCPUs in half, and keeping the same amount of RAM, and saving 34% of the costs.
Within AWS there are additional considerations on the network side. As shown here, available network performance follows the instance size and type. You may find yourself in a situation where memory and CPU are non-issues, but high network bandwidth is critical, and deliberately super-size an instance. Even in this case, though, you should think about if there is a way to split your workload into multiple smaller instances that are less expensive than a beastly machine selected solely on the basis of network performance.
You may also need to consider availability when determining your server sizing. For example, if you need to run in a high-availability mode using an autoscaling group you may be running two instances, either one of which can handle your full load, but both are only 50% active at any given time. As long as they are only 50% active that is fine - but you may want to consider if maybe two instances at half the size would be OK, and then address a surge in load by scaling-up the autoscaling group.
Keep Your Size on the Prize
For full cost optimization for your virtual machines, consider appropriate resource scheduling, server sizing, and sustained usage. You can easily save 50% just by going down one size tier - and this applies to production resources as well as development and test systems. Also, modernize your instance types. This is similar to rightsizing, in that you are changing to the same instance type in a newer generation of the same family, where cloud provider efficiency improvements mean lower costs. Finally, park instances when they are not in use. You can save 65% of the cost of a development or test virtual machine by just having it on 12 hours per day on weekdays.
This content is made possible by a guest author, or sponsor; it is not written by and does not necessarily reflect the views of App Developer Magazine's editorial staff.

Become a subscriber of App Developer Magazine for just $5.99 a month and take advantage of all these perks.
MEMBERS GET ACCESS TO
- - Exclusive content from leaders in the industry
- - Q&A articles from industry leaders
- - Tips and tricks from the most successful developers weekly
- - Monthly issues, including all 90+ back-issues since 2012
- - Event discounts and early-bird signups
- - Gain insight from top achievers in the app store
- - Learn what tools to use, what SDK's to use, and more
Subscribe here








