Enterprise
Replacing Scripted Software Deployments with a Jenkins Pipeline
Monday, July 18, 2016

|
Franklin Ivey |
When development begins on a new software project, it is often a popular choice to script many of the steps of the continuous integration (CI) process. As the project grows to require a more complex infrastructure, unit and end-to-end testing, and a robust, repeatable deployment procedure, simple scripts are no longer the best solution.
To save a large hit on productivity, a better alternative is to replace these scripts with a Jenkins build server and a pipeline onfiguration.
When it’s Time to Replace Scripts
There are a few obvious signs that it might be time to replace scripted deployment methods with something a little more robust.
- When It Doesn’t Scale: For every new piece added to an application, the scripts have to be updated. Whether you’re using bash, python, or something else, this can get out of hand quickly. Every line of code added to put new files in different locations, update permissions, and restart processes create more complexity and a greater risk of something going wrong.
- When It Becomes Unmaintainable: The increasing complexity, from things like the addition of conditional logic to alter the deployment based on the state of the system, inevitably leads to a set of scripts that only a handful of developers can interpret. A process like this that grows organically to quickly meet the immediate needs of deploying the application creates a big problem.
- When It Gets Expensive: In this case, the expense comes in the form of developer hours and productivity. The overhead required by the manual processes involved in preparing for and executing a release will begin to have a significant negative impact on new feature development.
Incorporating Jenkins in the CI Process
Most developers are probably already familiar with Jenkins as a build server and CI tool. Jenkins is most commonly used as the primary tool for building and testing code.
Before getting started on building a complicated pipeline, it is recommended that jobs that will be part of the pipeline be configured by following the guidelines for building a software project on the Jenkins Wiki. Jenkins also makes automatic triggering of build and test jobs very simple to configure. You can even chain those jobs together so that a new commit to your repository triggers a build, which then triggers a deploy to your test environment, and finally triggers an automated test run.
The problem with this approach is that there is still no clear visual of the flow of these jobs for one particular commit ID. You will find yourself viewing multiple executions of jobs that are linked together, trying to match commit IDs and timestamps to understand where your code is and which version was tested.
Using Pipelines
Using pipelines in Jenkins provides a solution to the problem of tracking a particular commit through the build ➔ deploy ➔ test process by creating an easily readable visual of the set of jobs that corresponds to each code change. A simple example of the visual that results from the Jenkins Pipeline Plugin looks like this:
Utilizing the pipeline method allows for the tracking, building, deploying, and test steps for a specific execution of the CI flow. You can even tag the commit that corresponds to an execution of the pipeline, store the artifacts that result from a build on that commit, and pass variables between steps in the pipeline. This is particularly helpful in ensuring that the CI process be made very granular, splitting different parts of the build and test execution into multiple jobs. Then, all that is needed is to pass a build tag for the artifacts between jobs, allowing for more parallelization, and resulting in a pipeline that looks more like this:
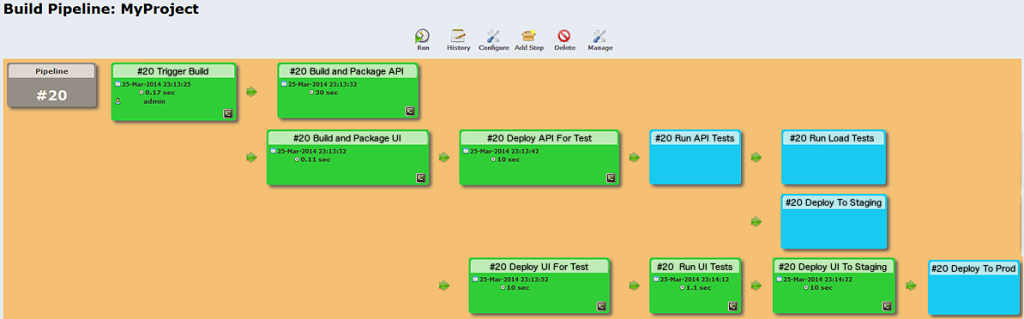
Each step in the pipeline could trigger multiple down-stream tasks, and evaluate conditions (based on things like build status and test results) to determine if the next steps should be executed. Manually triggered steps can then be used to deploy to staging and production environments after the successful execution of all other steps in the pipeline.
Using Jenkins and this pipeline strategy, bash scripts can be traded for a world in which each commit triggers a new pipeline execution, and a single button press puts the resulting tagged artifacts into service in production.
Adding Useful Plugins
When designing a pipeline, there are some other plugins that fit in very well with the pipeline concept and meet some important needs. For example, job execution can be delegated to Jenkins slave instances to run multiple pipelines in parallel. There should also be a way of storing builds in a central location, as well as a set of tools to enhance the deployment portion of the pipeline.
Here are a few of the most important of those plugins:
- Amazon EC2 Plugin: This plugin is extremely useful in delegating work from the master Jenkins node to dynamically allocated slave instances that can execute the steps in your pipeline. Slave instances are an absolute necessity when you have multiple code branches for feature development each triggering their own pipeline executions.
- Amazon S3 Plugin: S3 is a great place to store build artifacts and configuration information so that all of your environments can easily access these things. The S3 plugin allows the build steps in your pipeline to upload the resulting files so that the following jobs can access them with only a build ID or tag passed in as a parameter.
- Custom Tools Plugin: This is useful in combination with dynamically allocated slave instances for installing tools and packages like Javascript libraries or database migration tools that the deploy and test jobs might need to utilize. It is a good alternative to having these tools baked into the AMI that you use as a template for the Jenkins slave nodes, and it allows you to keep tools updated continually without having to think about it.
- Ansible Plugin: A configuration management platform is recommended for most of the deployment steps. Many teams make use of Ansible for this, and the Ansible plugin for Jenkins takes care of installing and updating Ansible on all nodes.
Read more: http://bandwidth.com
This content is made possible by a guest author, or sponsor; it is not written by and does not necessarily reflect the views of App Developer Magazine's editorial staff.

Become a subscriber of App Developer Magazine for just $5.99 a month and take advantage of all these perks.
MEMBERS GET ACCESS TO
- - Exclusive content from leaders in the industry
- - Q&A articles from industry leaders
- - Tips and tricks from the most successful developers weekly
- - Monthly issues, including all 90+ back-issues since 2012
- - Event discounts and early-bird signups
- - Gain insight from top achievers in the app store
- - Learn what tools to use, what SDK's to use, and more
Subscribe here








