Programming
Kernel Patching 101: How to Make Repairs Without System Downtime
Tuesday, January 5, 2016

|
Vojtech Pavlik |
Today, we increasingly rely on computers to control critical activities like stock trading, flight control or nuclear power plant management. These services must not fail or have outages, they must be “always on.” Redundant systems composed of components of independent origin are being used to prevent systemic errors that cause larger outages while hot-swappable components have been designed to allow replacing components without shutting down systems.
Live kernel patching is the software equivalent of hot-swappable physical components, as it allows replacing a faulty function inside the kernel without taking the system offline.
When to Use Kernel Patching?
Change management commonly recognizes three tiers of change:
- Incident response
- Emergency change
- Scheduled change
A system could be down or in the midst of being actively exploited and a corrective action is needed immediately – an incident response is required. In an emergency, while the system is still running, there is an identified risk that the system might crash or have a known vulnerability to attack, requiring an expedited action without delay. Scheduled changes are typically improvements that can wait until a window when the system is not needed.
Live patching provides that quick solution to incidents and emergencies caused by kernel issues and, in effect, turns the final resolution of such an issue into a scheduled change. This is crucial for customers with PCI-DSS, SSAE-16, ISO-27001 or other compliance and security certifications that mandate a timeliness of incident response.
Who Uses Kernel Patching?
A typical case for live patching is in memory databases, where the cost of reboot and, by extension, the value of avoiding a reboot is highest. The huge processing and analytics power of an in-memory database comes at a cost of having to load the complete dataset from disk to memory when the database is starting.
Redundancy and replication can mitigate externally visible downtime, however a delay in processing during failover is still measurable. Using live patching eliminates the delay and may turn out to be much more cost effective than owning a second, very large server that acts only as a hot spare.
Mission-critical infrastructure services are another use case. These typically are redundant, and the goal is to keep them fully redundant at all times. The redundancy is there to cope with failures. It is not a tool to be used by administrators routinely for introducing changes. Live patching can help by allowing IT to apply fixes without having to go through a reduced redundancy cycle.
Simulations and High Performance Computing (HPC) calculations with terabytes of data in flight and spread over thousands of systems often cannot afford to stop and save all that data to storage; nor is a rolling reboot of the whole HPC cluster advisable. Live patching can help to keep the calculation going if a bug in the kernel is causing instability in the cluster.
Live patching helps save on update costs, allowing IT to apply fixes in seconds, rather than hours or days to a large farm of servers.
Intro: kGraft
kGraft is a live patching technology developed by SUSE. kGraft is designed to be fast, cause no measurable interruption of service during patching, and is easy and transparent to use.
Simply installing a kGraft RPM package patches the kernel; upgrading the RPM package to a newer version updates the kernel to the next patch level; and downgrading the RPM package downgrades the patch level.
To achieve all design goals, constraints had to be put on what kGraft can do. Most importantly, the scope of patches that are be available as live patches is limited to CVE vulnerabilities rated at CVSS level6 and higher, and to bugs that could cause data corruption or system instability.
Internally, kGraft implements patching by using ftrace, a kernel tracing toolkit, to put a CALL instruction into a reserved space at the beginning of a function that it wants to replace, which then redirects the code flow into ftrace,, which in turns calls into kGraft upon any invocation of the to be replaced function.
kGraft then decides which replacement function should be called instead. This is much more reliable approach than changing all call sites that want to execute the function to call the replacement. There can be thousands of call sites inside the kernel, and identifying all is a nearly impossible task.
Creating Patches
There are two fundamental ways to create live patches: manual and automated.
Automated approaches save effort but tend to make patches larger than required and very hard to review for correctness. In any case, a semantic analysis of the patch must be done by a human, which mostly negates the saved effort by automating patch generation.
kGraft provides tools for automation. However, experience has shown that creating patches manually allows users to produce higher quality patches that can be fully independently reviewed in source form and proven to do exactly what they are intended to.
Since kGraft replaces functions inside the kernel, a starting point is to identify which functions need to be replaced.
It starts with including the required header files and then defines the following:
- A new version of a kernel function
- A structure containing the description of the patch, as well as a list of functions to replace
- The steps to initialize and clean up the module that uses the kGraft infrastructure to apply and remove the patch upon insertion and removal of the module into and from the Linux kernel
Caveats in Patch Creation
The first, very basic caveat in patch creation is inlining. A C compiler can decide that a certain function is small enough that instead of being called, it’s worth embedding it into the calling function whole. This is called inlining. If the inlined function contains a bug, the bug is replicated into any other function that it has been inlined into. This isn’t seen in the C source and is purely a compiler internal decision. All the affected functions need replacing now, not just the original.
The solution to this is DWARF debug information that is being built and archived together with the kernel contains all that is needed to know the compiler’s inlining decisions. It can be used to expand the list of functions that need to be replaced by the patch author.
Unexported symbols are another obstacle to watch for. These are symbols used within a kernel object that aren’t available outside of its scope for linking. Using such a function from a patch directly is thus impossible and requires a trick: by using the kallsyms infrastructure of the Linux kernel, it is possible to obtain the addresses of all symbols, including unexported symbols. Such symbols then can be called via those addresses.
IPA-SRA, or interprocedural scalar replacement of aggregates, is a feature that is as dangerous as its name sounds. It’s a compiler optimization that gives a significant performance boost, but it is also a disaster for patching. It can modify CALL instructions at the end of a function into JMP if the CALL is the last statement of a function. It can transform arguments passed by reference into arguments passed by value if the value is never changed, and it can create multiple variants of a function with fewer arguments, assuming a specific constant value for the removed argument allows for significant reduction of a function.
This is all recorded in DWARF, the same as inlining and only results in more effort for the patch author.
Patching in Detail
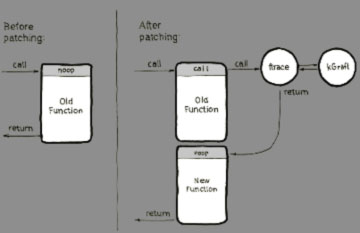
As mentioned earlier, kGraft uses the ftrace framework for call redirection. Ftrace on the x86-64 architecture uses ‘gcc -pg -mfentry’ to generate calls to __fentry__() at the beginning of every function, replacing all those calls with “NOP” instructions at boot and by that reserving space for call redirection in the future. When required, the “NOP” is automatically replaced with a “CALL” to ftrace. kGraft then registers a tracer with ftrace, taking control when a redirection is needed. And that’s it: a function call is redirected.
Gcc’s “-mfentry” argument is unique to the x86-64architecture. However, similar functionality is offered by “-mprofile-kernel” on the POWER64 architecture, or by “-mhotpatch” on s390x. Supporting ftrace and, by extension, kGraft is thus possible across all major architectures, including Aarch64 (ARM64).
The Final Hurdle
Using ftrace, it’s fairly straightforward to redirect a single function to a new version. But what happens when multiple functions require being changed simultaneously because they depend on each other? The dependency can be in the form of changed number or types of arguments, return type or even a semantic change not covered by programming language syntax. In this case, we need a consistency model. kGraft uses a consistency model called “leave kernel / switch thread.” Its main virtue is no interruption of service and no impact on the running system whatsoever.
In kGraft, we want to avoid calling a new function from an old one and vice versa: if the function prototype has changed, this would cause a system crash. We achieve it by remembering a “universe” flag for each thread of execution such as interrupts, user threads or kernel threads. Only when a thread reaches a safe point, where we know that no kernel function is being executed by that thread, can we switch the universe flag and the thread starts executing new functions.
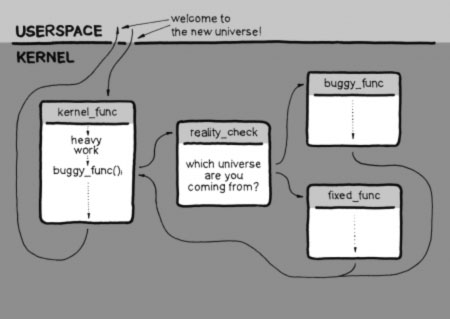
This safe point is the end of interrupt for interrupts, kernel exit/entry for user space threads and the so-called freezer for kernel threads. After applying a patch, threads migrate one by one to the new universe as they pass through their respective safe points. No stopping of anything is needed, and once everyone is in the new universe, kGraft declares patching complete.
But what if a thread never does anything and never passes a safe point? We call these threads “eternal sleepers.” They might be server daemons waiting for a request that never comes or getties on consoles where no one ever logs in or threads for handling situations that never arise. They just wait for their cue and sleep inside the kernel forever.
Patching cannot be declared complete until even these threads are moved over to the new universe. kGraft has to wake them up. This is done by sending them a signal, “SIGKGRAFT.” This special signal wakes up the thread and causes it to attempt to exit the kernel to handle the signal, thus passing a safe point. At the safe point, kGraft catches the signal and returns the thread back to the kernel. The sleeping user space application never notices, its thread is safely migrated, and success can be declared.
Many other consistency models are also being proposed and implemented. One is the Ksplice consistency model (now categorized as “leave patched set / switch kernel”), which achieves consistency simply by stopping the whole system for patching. Stopping isn’t enough, though. After stopping, every thread needs to be checked to determine whether it is executing any of the to be patched functions. If it is, the kernel is resumed and stopped later to try again. This model is as safe as kGraft’s, but can cause up to 40ms of interruption of service for each patch, and fails to patch if eternal sleepers are sleeping in any of the patched functions.
Read more: https://www.suse.com/products/live-patching/
This content is made possible by a guest author, or sponsor; it is not written by and does not necessarily reflect the views of App Developer Magazine's editorial staff.

Become a subscriber of App Developer Magazine for just $5.99 a month and take advantage of all these perks.
MEMBERS GET ACCESS TO
- - Exclusive content from leaders in the industry
- - Q&A articles from industry leaders
- - Tips and tricks from the most successful developers weekly
- - Monthly issues, including all 90+ back-issues since 2012
- - Event discounts and early-bird signups
- - Gain insight from top achievers in the app store
- - Learn what tools to use, what SDK's to use, and more
Subscribe here








