

.jpg)
Key findings of the Apache Spark market research study
Friday, November 11, 2016

|
Christian Hargrave |
In order to better understand Apache Spark’s growing role in big data, Taneja Group conducted a major market research project, surveying approximately 7,000 people. The sample was made up of technical and managerial job roles from around the world directly involved in big data.
The survey, which received an overwhelming response, explored experiences with and intentions for Spark adoption and deployment, current perceptions, favored vendors, and the future of Spark itself. Cloudera, the global provider of the fastest, easiest, and most secure data management and analytics platform built on Apache Hadoop and the latest open source technologies, which sponsored the market research project, and just announced the findings of the study.
Survey Results
Key findings of the Apache Spark Market Research Study include a high level of growth and momentum for Spark usage beyond expected data processing/engineering ETL workloads and a future transition to cloud deployments. Other noteworthy findings include:
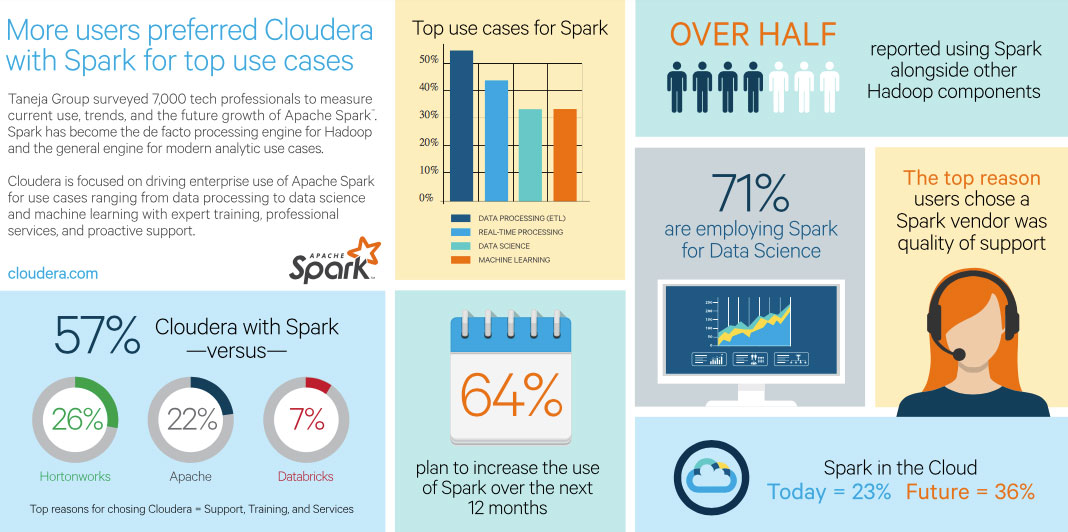
- Nearly one-half of all respondents, 54 percent, are already actively using Spark. Of those presently using Spark, 64 percent say it’s proving invaluable and they intend on increasing usage of Spark within the next 12 months.
- New Spark user adoption is also growing with 4 out of 10 people familiar with the big data project saying that they plan to deploy Spark in the very near term.
- 57 percent rely on Spark, as provided by Cloudera, for their most important use cases, over twice the next three Apache Hadoop vendors combined. Customers that chose Cloudera over other solutions noted its regulatory-ready security and governance model, its stability and performance, its cloud portability and its integration with a complete suite of data processing, query, analytic and machine learning services as key factors.
- Aside from the expected data processing/engineering/ETL workloads which make up 55 percent of reported Spark use today, the top active Spark initiatives include real-time stream processing, exploratory data science, and the emergence of Spark for machine learning. These are all areas where Cloudera continues to invest.
- Barriers to adoption and challenges remain the same however, and are largely attributed to the big data skills gap and the ability to consume relevant training in a variety of formats (online, in-person, conference or tradeshow). Cloudera trains more Apache Spark professionals than any other Hadoop vendor and supports them through professional services, value consulting, and a wide breadth of partners.
The survey also details the elevated role of the public cloud and Spark: “Interestingly, while on-premises Spark deployments dominate today there is a strong interest in transitioning many of those to cloud deployments going forward,” said Matchett. “Overall Spark deployment in public/private cloud (IaaS or PaaS) is projected to increase significantly from 23% today to 36% in the future.”
Read more: http://cloudera.com

Become a subscriber of App Developer Magazine for just $5.99 a month and take advantage of all these perks.
MEMBERS GET ACCESS TO
- - Exclusive content from leaders in the industry
- - Q&A articles from industry leaders
- - Tips and tricks from the most successful developers weekly
- - Monthly issues, including all 90+ back-issues since 2012
- - Event discounts and early-bird signups
- - Gain insight from top achievers in the app store
- - Learn what tools to use, what SDK's to use, and more
Subscribe here








